Melhoramos nosso produto de categorização com técnicas de machine learning. Nosso motor é agora capaz de analisar milhões de pontos de dados transacionais em segundos e transformá-los em insights precisos e acionáveis para nossos clientes.
Categorização de dados é o processo de organizar as transações financeiras de acordo com seus tipos, como alimentação, compras pessoais, contas da casa, etc. Isso é muito útil para empresas de gerenciamento de finanças pessoas e plataformas de contabilidade, que necessitam de descrições precisas das transações dos usuários.
Na primeira versão do nosso produto, a categorização das transações estava sendo feita através de um sistema baseado em regras (RBSs) manual. Porém, definir, atualizar e deletar essas regras foi se tornando uma tarefa cada vez mais complexa à medida que a quantidade aumentava, o que alongava o tempo de turnaround.
Com o objetivo de aperfeiçoar a nossa categorização, resolvemos recorrer ao machine learning buscando resultados em cinco áreas principais: cobertura, precisão, número de categorias, velocidade de categorização e frequência de manutenção.
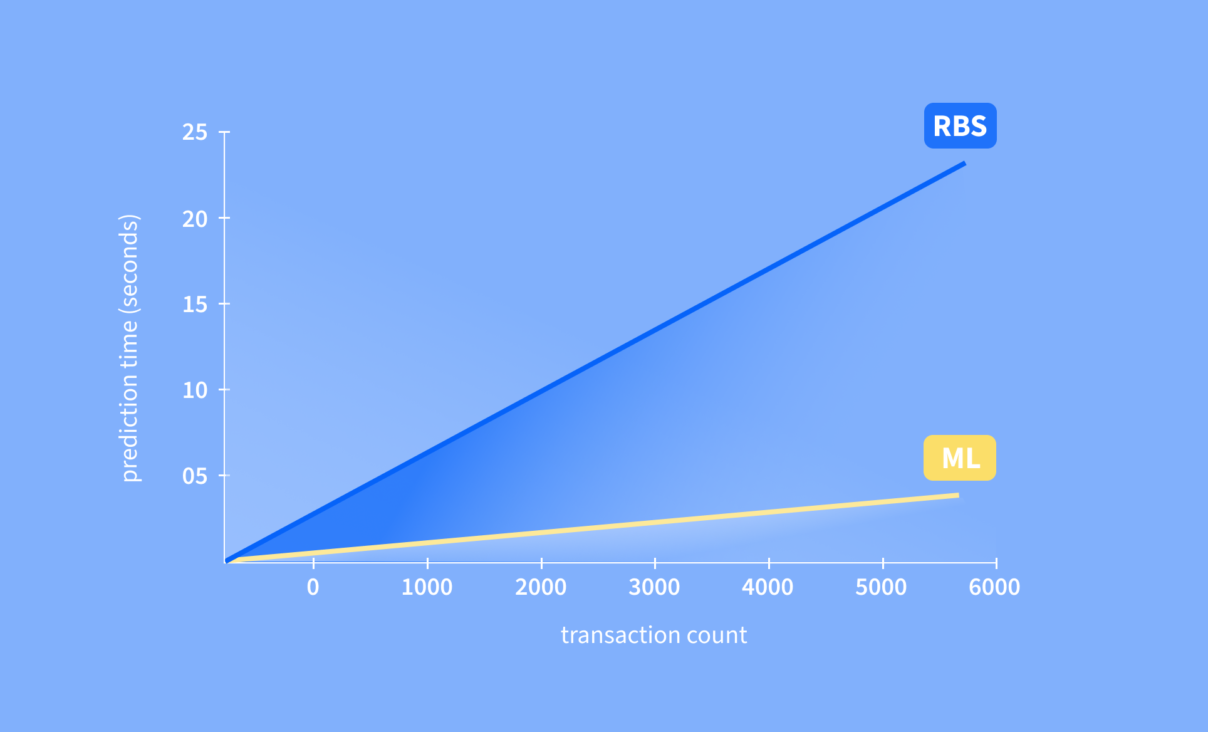
Um dos objetivos mais importantes era reduzir o tempo de processamento do produto, ou seja, analisar mais transações em um mesmo intervalo. Com a implementação de uma arquitetura de machine learning, hoje podemos processar 14 vezes mais transações do que antes, no mesmo período de tempo.
Índice
- O que mudou
- Por que mudamos
- Como funciona
- Os resultados: melhor tempo de turnaround
- O que vem a seguir?
O que mudou
Implementamos uma pipeline de categorização em torno de machine learning e técnicas de processamento de linguagem natural.
Esse novo sistema usa BPE, a mesma usada no GPT2, para a tokenização e LightGBM, um algoritmo moderno baseado em árvores de decisão, para a classificação. Tokenização no jargão técnico significa traduzir palavras em informações úteis para alimentar o modelo de machine learning. Antes disso, estávamos avaliando manualmente as mudanças no sistema e seu desempenho.
Além disso, a adaptação de dados não vistos de novas fontes significava criar manualmente regras para cada um dos padrões de transação que existiam na nova fonte. Este processo era longo, tedioso e não escalável.
Por que mudamos
Decidimos por a mão na massa porque queríamos melhorar nosso tempo de turnaround, ou seja, o tempo necessário para iterar em nossa categorização.
Visávamos experimentar novas fontes de dados, novas categorias e taxonomias. Com a nova versão, nosso processo de categorização se tornou muito mais robusto e reproduzível.
Este também foi o primeiro passo para desenvolver ainda mais as funcionalidades de machine learning da Belvo e tornar esta tecnologia um elemento-chave no nosso conjunto de ferramentas.
Como funciona
Bom, o novo modelo consiste em quebrar as descrições das transações em pedaços menores do que as palavras, que vamos chamar por aqui de sub-palavras. Quando os dados ou descrições de transações estão em estado bruto, as palavras geralmente parecem incompletas ou fundidas entre si.

Ao quebrar cada palavra "aparente" em sub-palavras, podemos contornar o problema acima e focar nas informações contidas nelas. Em seguida, examinamos as sub-palavras mais comuns e nos concentramos naquelas que contêm mais informações para a tarefa em questão.
Essas sub-palavras e alguns outros atributos da transação são então usados para treinar o modelo. É feito de centenas de pequenos classificadores que trabalham juntos focando tanto na minimização dos erros de classificação para cada categoria quanto na correção dos erros introduzidos por outros classificadores no modelo.
Orientamos o processo de aprendizagem usando uma métrica interna que garante que todas as categorias sejam tratadas de forma justa, independentemente da sua representação nos dados. Por exemplo, algumas categorias são mais comuns, como transferências, renda e pagamentos, ou investimentos e poupança. Entretanto, nossa métrica-guia aumentou o foco nas categorias que são de maior interesse para nossos clientes.
Tudo isso foi implementado através de uma "pipeline click-to-run", que quer dizer que podemos treinar um novo modelo e avaliar os resultados com um único comando que nos ajuda a poupar tempo e a ser mais eficientes.
Os resultados: melhor tempo de turnaround
Com o processo totalmente automatizado, agora é possível introduzir alterações em qualquer ponto da pipeline e avaliar os resultados em questão de minutos. Também temos a possibilidade de alterar os dados a partir dos quais criamos a classificação, a forma como os processamos, os modelos que usamos para classificá-los, ou ainda adicionar critérios de avaliação e obter resultados com uma única tecla em questão de minutos.
Esta automatização nos permite experimentar, descobrir melhores soluções e fornecer mais valor aos nossos clientes.
Desde o início, escolhemos uma arquitetura que nos ajudasse adaptar, de forma mais rápida, dados antes não vistos de novas fontes ou novos casos de uso. Conseguimos evoluir um processo que poderia levar meses, muito trabalho manual e refinamento de regras em um processo que pode ser realizado em questão de semanas.
As tecnologias que fomos capazes de construir são de última geração e aproveitam plenamente as características que as CPUs modernas oferecem. Isto significa que aumentamos o rendimento do modelo em uma ordem de grandeza.
De agora em diante, podemos processar 14 vezes mais rápido transações em português e 7 vezes mais transações em espanhol.
O que vem a seguir?
Já estamos aplicando estes avanços na construção de uma nova taxonomia de categorização mais alinhada às necessidades dos nossos clientes e com mais detalhes das transações, fornecendo uma categoria e uma subcategoria para cada uma delas.
Para te dar um spoiler sobre o que está vindo por aí, estamos trabalhando na criação de um categorizador para um caso de uso específico. E, quem sabe mais para frente, será até mesmo permitir que nossos clientes criem categorizadores e taxonomias para suas necessidades específicas de dados. Fique atento!