We improved our categorization product with machine learning techniques. Our engine is now capable of analyzing millions of transactional data points in seconds and turn them into accurate and actionable insights for our customers.
Data categorization is the process by which we organize financial transactions into a set of defined groups, such as personal shopping or bills and utilities. This is particularly useful for clients such as personal finance management companies and accounting platforms, for which providing accurate descriptions of their end-users transactions is key.
For the first version of our product, we were categorizing transactions with manually described rules based on expert knowledge. But defining, updating and deleting those rules was getting more and more complex as their number increased and the turnaround time was getting longer.
In order to improve our product and its capabilities, we decided to explore how machine learning could allow us to deliver good results in five main areas: coverage, accuracy, number of categories, categorization speed and maintenance frequency.
One of our key goals was to reduce the processing time of the product, which means analyzing more transactions in the same amount of time. Now, thanks to the implementation of a machine learning architecture, we have been able to speed up our categorization process. In other words, we can process 14 times faster transactions for the same amount of time.
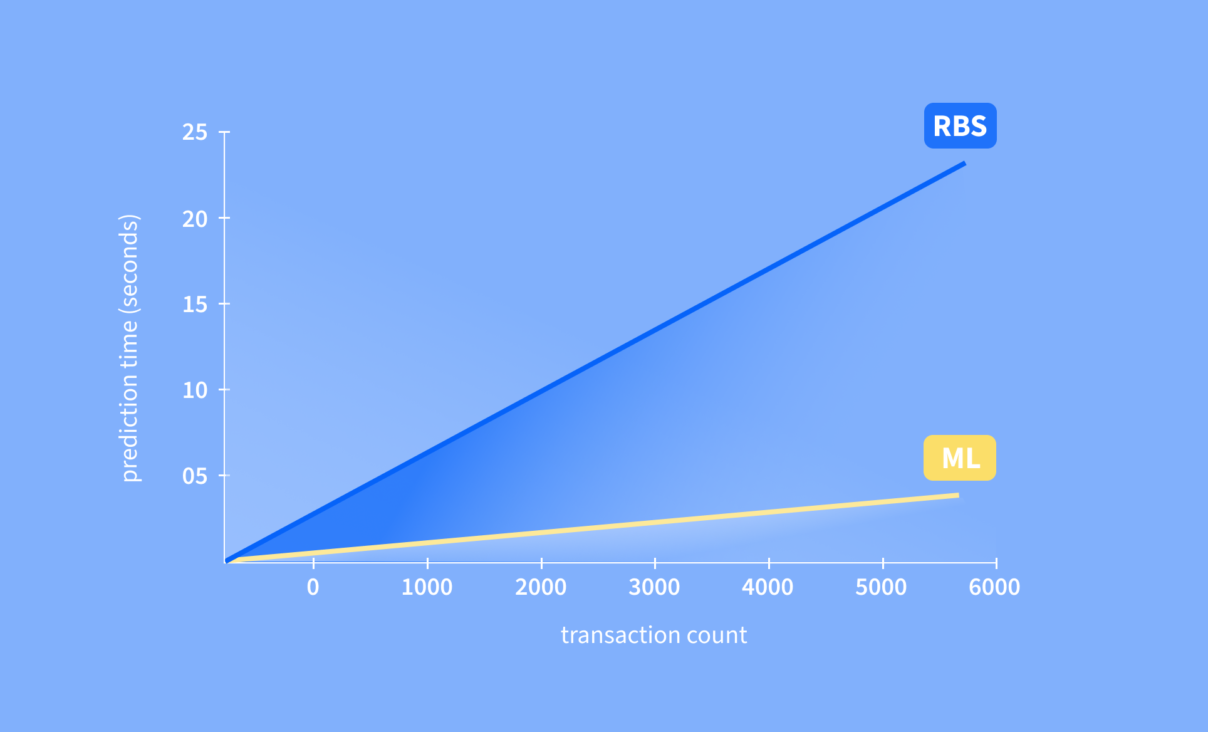
Table of Contents
What’s new
We implemented a whole pipeline for categorization around machine learning and natural language processing techniques.
The new system uses BPE, which is the same as used by GPT2 for tokenization and LightGBM, a modern algorithm based on decision trees, for classification. Tokenization in technical jargon means translating words into useful information to feed the machine learning model. Previously to this, we were manually evaluating the changes in the system and its performance.
Additionally, adapting to unseen data from new sources meant manually creating rules for each of the transaction patterns that existed in the new source. This process was long and tedious and not scalable.
Why have we done it
We decided to get our hands in the game because we wanted to improve our turnaround times, which means we wanted to reduce the time it takes to iterate on our categorization product.
The new version would allow us to experiment with new data sources, new categories and taxonomies. Thanks to it, our categorization improvement process is much more robust and reproducible.
It was also the first step into further developing Belvo’s machine learning capabilities and making this technology a key element of our toolset.
How does it work
The new model is based on the idea of breaking down transaction descriptions into pieces that are smaller than words (we'll call them subwords). With raw transactional data or descriptions, words usually appear incomplete or merged together.

By breaking each "apparent" word into subwords, we could circumvent the problem above and focus on the information contained in those. Then we looked into the more common subwords and focused on those that contain more information for the task at hand.
Those subwords and some other transaction attributes are then used to train the model. It is made of hundreds of small classifiers that work together focusing on both minimizing the classification errors for each category and correcting the errors introduced by other classifiers in the model.
We guided the learning process by using an in-house metric that ensures that all categories are treated fairly, regardless of their representation in the data. For example, some categories are more common, such as transfers, income and payments or investments and savings. However, our guiding metric increased the focus on those categories that are of most interest to our customers.
All of this has been implemented in a click-to-run pipeline. Because it means that we can train a new model and evaluate the results with a single command which helps us to save time and be more efficient.
The results: better turnaround times
Because we automated the whole process, introducing a change at any point of the pipeline and evaluating the results can now be done in a matter of minutes. We also have the possibility to change the data from which we create the classificator from, the way we process it, the type of model we use to classify the data, or even add evaluation criteria and get results with a single key press in a matter of minutes.
It allows us to experiment, discover better solutions and provide a much higher value to our customers.
From the beginning, we choose an architecture that helps us to adapt to previously unseen data from new sources or new use cases much faster. We managed to turn a previous process that could take months, a lot of manual work and refinement of rules into one that can be performed in a matter of weeks.
The technologies we have been able to build are state-of-the-art and take full advantage of the features that modern CPUs offer. This means we increase the model throughput by an order of magnitude.
From now on, we can process 14 times faster transactions in Portuguese and 7x more transactions in Spanish.
What’s next?
We’re already looking at taking advantage of these advancements to build a new category taxonomy. We want it to be more aligned with our customer needs, with higher details on the transactions by providing a category and a subcategory for each of them.
To give you a sneak peek at what we’ll be working on: we’ll look at creating a categorizator for a specific use case. And maybe, even allow our customers to create categorizators and taxonomies for their specific data needs - stay tuned!