Hemos mejorado nuestra categorización de producto con técnicas de machine learning. Ahora nuestra tecnología es capaz de analizar millones de datos transaccionales en segundos y convertirlos en información precisa y procesable para nuestros clientes.
La categorización de datos es el proceso donde se organizan las transacciones financieras en categorías como facturas, compras personales o servicios públicos. Esto es especialmente útil para compañías que se dedican a la gestión de finanzas personales o a la contabilidad, que necesitan proporcionar descripciones detalladas de las transacciones de sus usuarios.
Para la primera versión de nuestro producto, clasificamos las transacciones con reglas descritas manualmente. Pero la definición, actualización y supresión de esas normas se hacía cada vez más compleja a medida que aumentaba su número.
Con el objetivo de mejorar las capacidades de nuestro producto, decidimos explorar cómo el machine learning nos permite ofrecer buenos resultados en cinco ejes importantes: cobertura, precisión, número de categorías, velocidad de categorización y frecuencia de mantenimiento.
Uno de nuestros principales objetivos era reducir el tiempo de procesamiento del producto, es decir, analizar más transacciones en el mismo tiempo. Ahora, gracias a la implementación de una arquitectura de machine learning, hemos podido acelerar nuestro proceso de categorización. En otras palabras, ahora podemos procesar transacciones 14 veces más rápido durante el mismo periodo de tiempo.
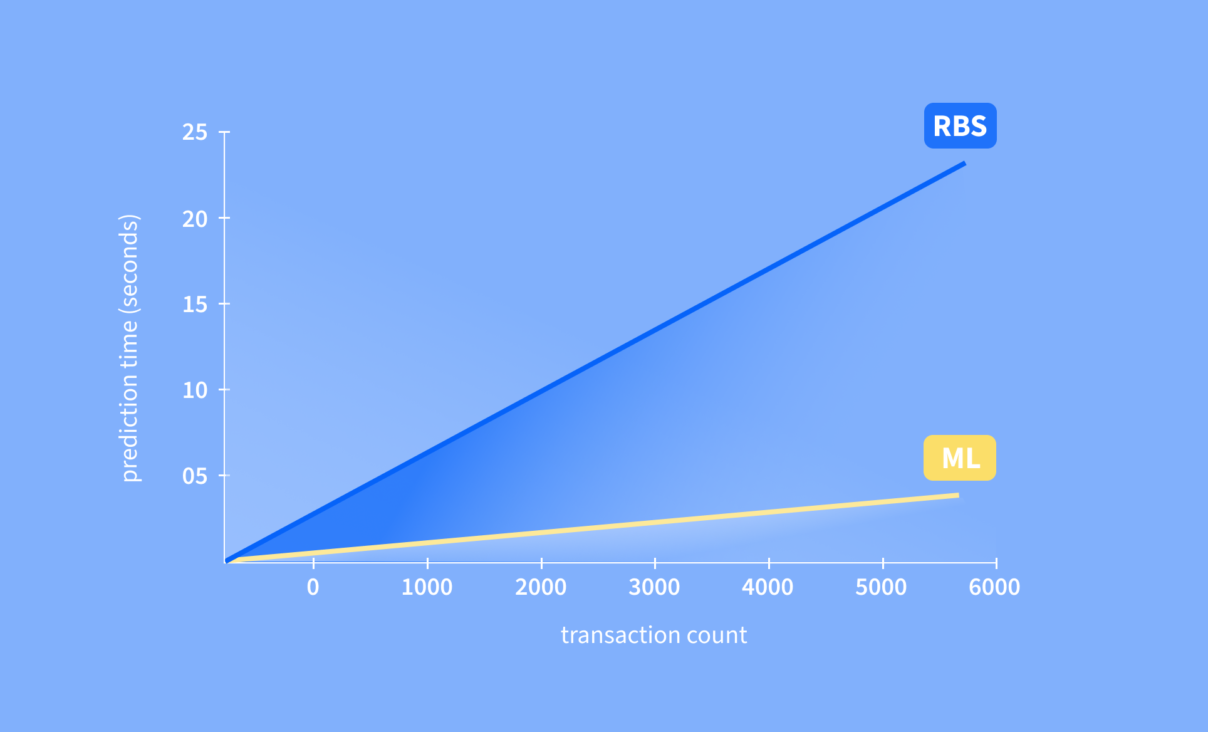
Tabla de contenidos
- ¿Qué hay de nuevo?
- ¿Por qué lo hemos hecho?
- ¿Cómo funciona?
- ¿Cuáles son los resultados?
- Lo que viene después
¿Qué hay de nuevo?
Hemos puesto en marcha todo un proceso de categorización basado en técnicas de machine learning y de procesamiento del lenguaje natural.
El nuevo sistema utiliza BPE, que es el mismo que utiliza GPT2 para la tokenización y LightGBM, un algoritmo moderno basado en árboles de decisión, para la clasificación. La tokenización significa, en jerga técnica, traducir las palabras en información útil para alimentar el modelo de machine learning.
Antes de esto, evaluábamos manualmente los cambios en el sistema y su rendimiento. Además, la adaptación a nuevos datos no vistos previamente de nuevas fuentes suponía crear manualmente reglas para cada uno de los patrones de transacción que íbamos encontrando. Este proceso era largo y tedioso, y no era escalable.
¿Por qué lo hemos hecho?
Decidimos apostar por este nuevo enfoque para mejorar nuestros tiempos de procesamiento. En otras palabras, queríamos reducir el tiempo de iteración de nuestro producto de categorización.
Esta nueva versión nos permite experimentar con nuevas fuentes de datos, nuevas categorías y taxonomías más fácilmente. De esta forma, nuestro proceso de mejora de la categorización es mucho más robusto y reproducible.
Esto también ha supuesto el primer paso para seguir desarrollando las capacidades de machine learning en Belvo y convertir esta tecnología en una pieza elemental de nuestro conjunto de soluciones.
¿Cómo funciona?
El nuevo modelo se basa en la idea de descomponer las descripciones de las transacciones en trozos más pequeños que las palabras (los llamaremos subpalabras). Con los datos o descripciones transaccionales en bruto, las palabras suelen aparecer incompletas o fusionadas.

Al dividir cada palabra en subpalabras, pudimos evitar el problema anterior y centrarnos en la información que contienen. Luego examinamos las subpalabras más comunes y nos centramos en las que contienen más información para la tarea en cuestión.
Estas subpalabras, junto con algunos otros atributos de la transacción, se utilizan entonces para entrenar el modelo. Está formado por cientos de pequeños clasificadores que trabajan juntos, centrándose tanto en minimizar los errores de clasificación de cada categoría como en corregir los errores introducidos por otros clasificadores en el modelo.
Hemos guiado el proceso de aprendizaje utilizando una métrica interna que garantiza que todas las categorías sean tratadas de forma justa, independientemente de su representación en los datos. Por ejemplo, algunas categorías son más comunes, como transferencias, ingresos y pagos o inversiones y ahorros. Sin embargo, nuestra métrica orientadora aumentó la atención a las categorías que más les interesan a nuestros clientes.
Todo esto se ha implementado en un pipeline "click-to-run". Esto significa que podemos entrenar un nuevo modelo y evaluar los resultados con un solo comando, lo que nos ayuda a ahorrar tiempo y ser más eficientes.
¿Cuáles son los resultados?
Como hemos automatizado todo el proceso, introducir un cambio en cualquier punto del pipeline y evaluar los resultados puede hacerse ahora en cuestión de minutos. También tenemos la posibilidad de cambiar los datos a partir de los cuales creamos el clasificador, la forma en que los procesamos, el tipo de modelo que utilizamos para clasificar los datos, o incluso añadir criterios de evaluación y obtener resultados con solo pulsar una tecla en minutos.
Esto nos permite experimentar, descubrir mejores soluciones y ofrecer un valor mucho mayor a nuestros clientes.
Desde el principio, elegimos una arquitectura que nos ayuda a adaptarnos mucho más rápido a datos no vistos anteriormente procedentes de nuevas fuentes o nuevos casos de uso.
Hemos conseguido convertir un proceso anterior que podía llevar meses, mucho trabajo manual y el perfeccionamiento de las reglas, en uno que puede realizarse en cuestión de semanas.
Las tecnologías que hemos podido construir son de última generación y aprovechan al máximo las prestaciones que ofrecen las CPU modernas. Esto significa que aumentamos el rendimiento del modelo en un orden de magnitud.
A partir de ahora, podemos procesar 14 veces más rápido las transacciones en portugués y 7 veces más las transacciones en español.
Lo que viene después
Ya estamos pensando en aprovechar estos avances para construir una nueva taxonomía de categorías. Queremos que esté más alineada con las necesidades de nuestros clientes, con mayores detalles sobre las transacciones al proporcionar una categoría y una subcategoría para cada una de ellas.
Para darles un adelanto de lo que vamos a trabajar: vamos a explorar la creación de un categorizador para un caso de uso específico. Y tal vez, incluso permitir a nuestros clientes crear categorizadores y taxonomías para sus necesidades específicas de datos - ¡estén atentos!